Gpt4all: 一个在基于LLaMa的约800k GPT-3.5-Turbo Generations上训练的聊天机器人
基于 LLaMa 的 ~800k GPT-3.5-Turbo Generations 训练助手式大型语言模型的演示、数据和代码

Try it yourself
Download the CPU quantized gpt4all model checkpoint: gpt4all-lora-quantized.bin
gpt4all-lora-quantized.bin 这个文件有 4.2GB ,存放在 amazonaws 上,下不了自行科学
Clone this repository down and place the quantized model in the chat directory and start chatting by running:
cd chat;./gpt4all-lora-quantized-OSX-m1 on M1 Mac/OSX
cd chat;./gpt4all-lora-quantized-linux-x86 on Windows/Linux
To compile for custom hardware, see our fork of the Alpaca C++ repo.
Note: the full model on GPU (16GB of RAM required) performs much better in our qualitative evaluations.
三步曲
- 下载 gpt4all-lora-quantized.bin 下列网址都可尝试
- 下载 gpt4all-lora-quantized-linux-x86 或 其它平台程序
- 把上面两个文件放在一个文件夹里,运行
-rw-r--r-- 1 root root 4212732137 Mar 29 11:48 gpt4all-lora-quantized.bin
-rwxr-xr-x 1 root root 410392 Mar 29 11:49 gpt4all-lora-quantized-linux-x86
例如我让它用python写一个一元一次方程:
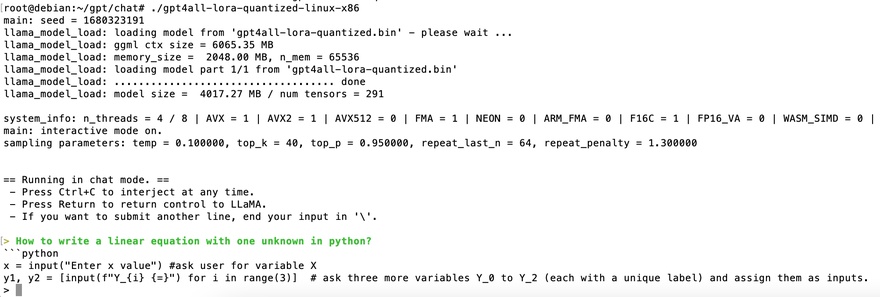
效果还不错(不管它写得对不对,总算是写出来了),主要是依赖训练语料!
像官方 readme 里的示例问题,回答效果很好

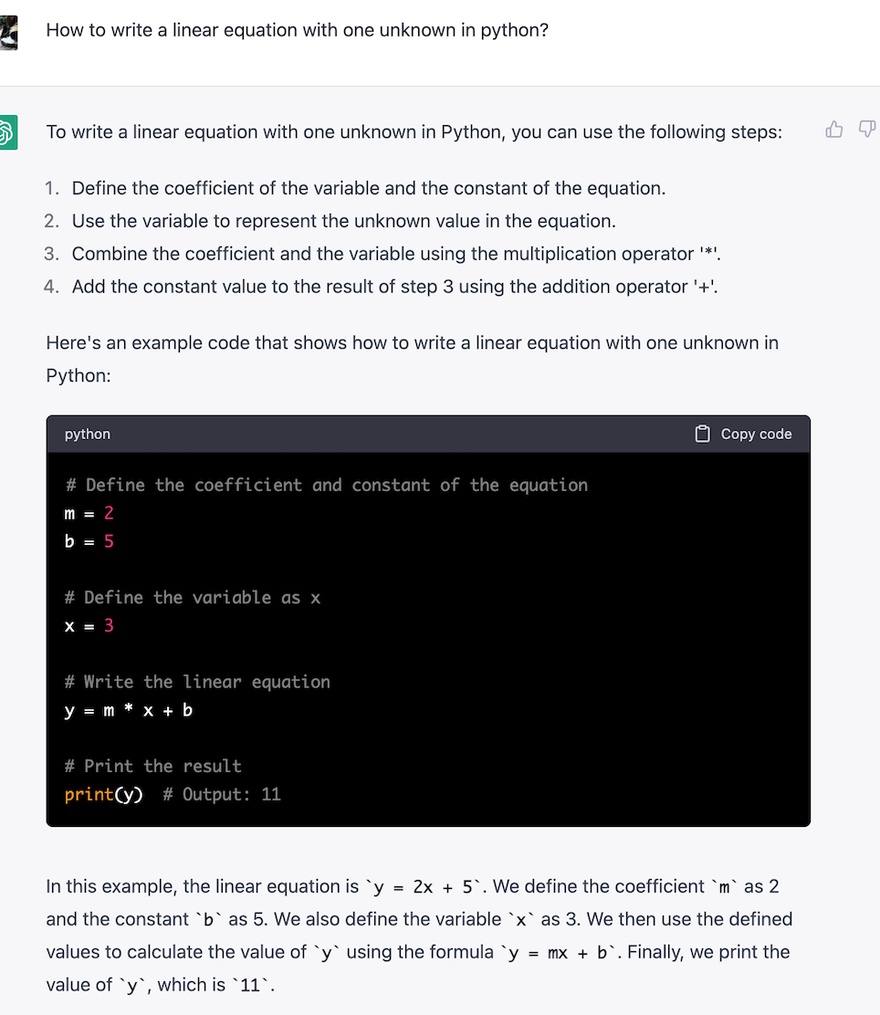
在 https://chat.openai.com/ 上提问的结果,对比一下:
问题: How to write a linear equation with one unknown in python?
- 传送门 gpt4all https://github.com/nomic-ai/gpt4all
See Also
Nearby
- 上一篇 › MiniGPT-4 开篇一张图剩下全靠编
- 下一篇 › JS 支持跨浏览器推送