Golang实现的Simhash去重算法库
Simhash来自于Google Moses Charikar发表的一篇论文 “detecting near-duplicates for web crawling” 中提出了simhash算法,专门用来解决海量数据的去重任务。这个算法通过将一个文档转化为一个64位的二进制特征串,然后比较两个文档的特征串,如果这两个文档的特征串的海明距离小于某个值(一般来讲这个值为3),则说明这是相似文档。
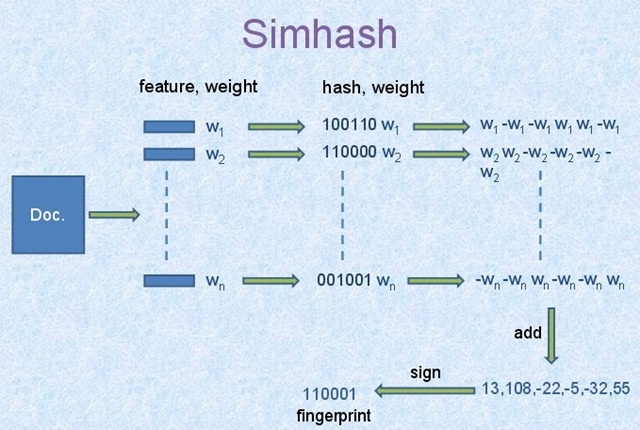
算法过程大概如下:
- 将Doc进行关键词抽取(其中包括分词和计算权重),抽取出n个(关键词,权重)对, 即图中的(feature, weight)们。 记为
feature_weight_pairs = [fw1, fw2 … fwn],其中fwn = (feature_n,weight_n)。 hash_weight_pairs=[ (hash(feature), weight) for feature, weight in feature_weight_pairs ]生成图中的(hash,weight)们, 此时假设hash生成的位数bits_count = 6(如图);- 然后对
hash_weight_pairs进行位的纵向累加,如果该位是1,则+weight,如果是0,则-weight,最后生成bits_count个数字,如图所示是[13, 108, -22, -5, -32, 55], 这里产生的值和hash函数所用的算法相关。 [13,108,-22,-5,-32,55] -> 110001这个就很简单啦,正1负0。
Simhash的算法简单的来说就是,从海量文本中快速搜索和已知simhash相差小于k位的simhash集合,这里每个文本都可以用一个simhash值来代表,一个simhash有64bit,相似的文本,64bit也相似,论文中k的经验值为3。该方法的缺点如优点一样明显,主要有两点,对于短文本,k值很敏感;另一个是由于算法是以空间换时间,系统内存吃不消。
go 库推荐
0
See Also
Nearby
- 上一篇 › vanilla js 最轻快的 js 框架
- 下一篇 › 记一下youBBS第三次程序改写