提取网页正文的测试
《Golang实现在线提取新闻网页正文》 https://pylist.com/tools/gogne 是个不错的提取网页正文在线工具。
做了一下测试,对于大多数新闻页面或主体明确的网页都能抓取,如新浪、网易、凤凰、澎湃新闻……
我拿youbbs 的一篇文章 https://www.youbbs.org/t/3227 测试。
默认抓到的是 5楼 的回复,因为5楼的内容最多。

我只想要主贴,填写忽略的 html.node

写的 xpath 是 //*[@class="commont-item"],提取到了主贴。
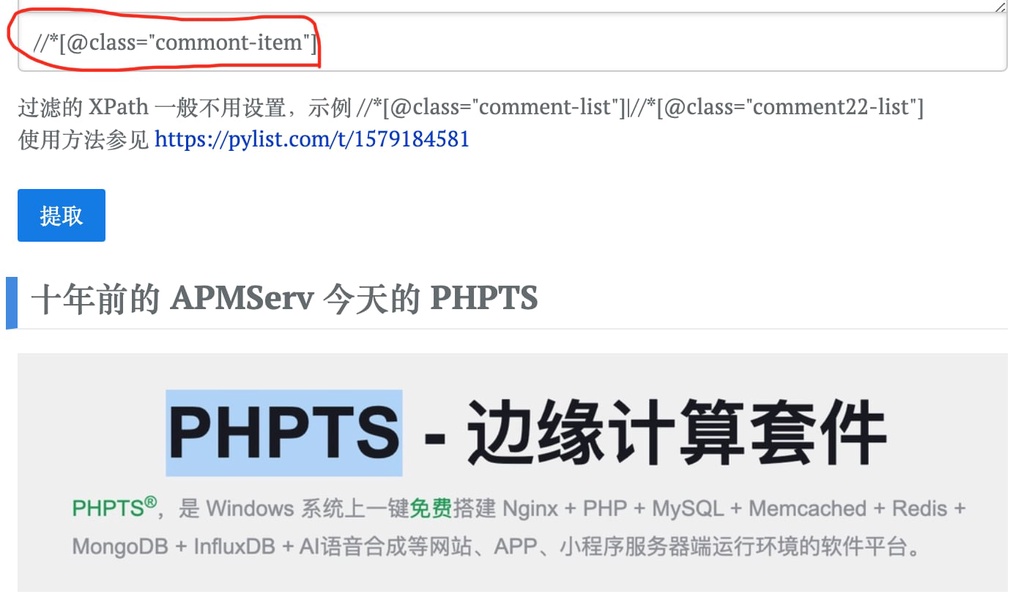
但是会把标签与相关帖子也提取了,

再填写 xpath 忽略掉这两个内容
//*[@class="commont-item"]|//*[contains(@class, "mytag")]|//*[@class="has_adv"]
终于提取成功!!刚开始感觉挺复杂,回头看看youbbs 正文的源码
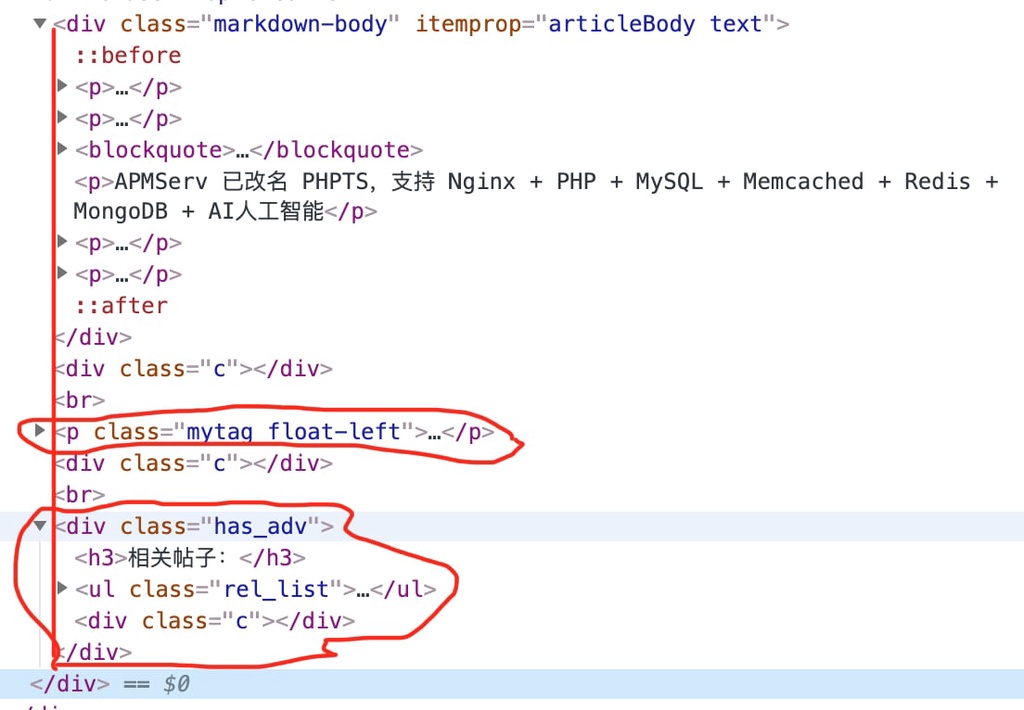
标签、相关帖子与正文在同一个 div 里,被抓到也可以理解。
上面的例子可以引申一个想法,好的页面结构利于搜索引擎的抓取分析,想让搜索引擎抓取哪些东西,就得把它们框得清晰一些。当然,搜索引擎也不会那么傻,也会自己学习判断。
0
See Also
Nearby
- 上一篇 › 能否出个楼主可编辑帖子正文的功能
- 下一篇 › 十年前的 APMServ 今天的 PHPTS
然后goyoubbs成为了最容易采集的网站之一。哈哈
@root #1 一开始把tag与相关帖子放在同一个
div里已经考虑这个问题,好处是可以在被采集的内容里添加更多链接,不好的可能是,初级爬虫工程师去除不了tag和相关帖子,干脆不采了。现在采集及内容提取技术越来越好了,只要内容有足够大的价值,多复杂也能采。@youbbs #2 恩。也是 一般采集工具都可以采集,复杂一点的中正则表达式也可以过滤不要的信息
以我开发了十几个爬虫的经验来看,基本上没什么网站是抓不了的
做这些还不如做内容