自己撸一份反爬虫方案
这两天在折腾这个东西,顺便记一下。这里都是在 golang web 框架下实现。
- 了解蜘蛛,有些蜘蛛是抓内容作为自己的内容,有的是做数据分析...
- 细化路由,对指定路由限制,在
handle套个中间件,反爬逻辑都在这个中间件里实现 - 用户资料采集,直接能抓到的就只有两个信息:IP 和 UserAgent
- 白名单和黑明单,针对网站的目标用户特点及流量特征,做
IP 段的白名单和黑名单, UserAgent 的黑名单,UserAgent 可以随意设置,因此不做白名单,这里涉及到真假蜘蛛的识别,要根据 IP 反查收集信息。 - 做一个 ip rate limit 限制,分时段限制,比如每小时访问不超过100次,每天不超过 500 次,这个还是挺关键
- 自动管理,对可信任的爬虫来访时,自动添加其识别信息到相关白名单
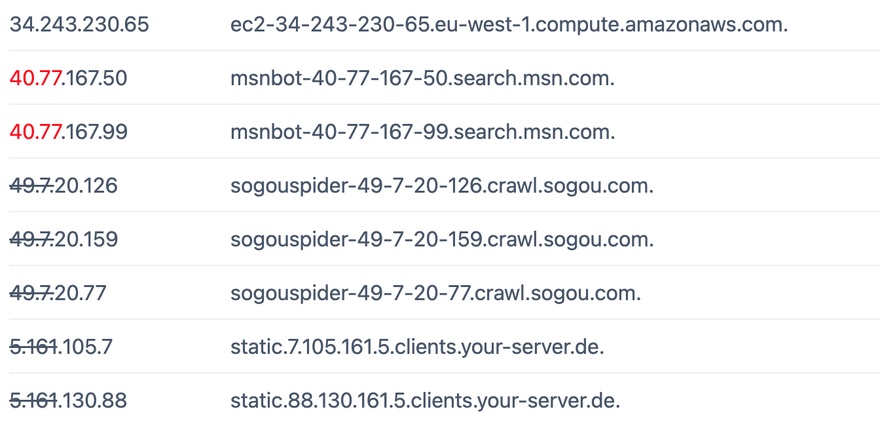
一连串下来,网站基本安静。
流程
- 解析 User-Agent
- 检测 UA 里某个关键字是否在黑名单里
- 获取 IP
- 检测 IP 特征是否在黑名单里
- 检测 IP 特征是否在白名单里
- 到这里大部分恶意爬虫已经被排除
- 根据 IP 做访问记录,
- 根据访问记录筛选数据做程序分析(DNS 反查)及人工分析,完善黑白名单设置
0
See Also
- SQLite 分布式部署方案
- leveldb + python 的数据库方案
- Chrome headless 模式,爬虫、网页截图、生成PDF 利器
- Colly: Golang编写的简单而强大的Web爬虫框架
- 推荐个python的爬虫教程?
Nearby
- 上一篇 › 绿色轻量级的程序守护程序joker
- 下一篇 › 谷歌翻译转移了